Speculative Decoding in MLX with DFlash
An empirical evaluation of speculative decoding on Apple Silicon, across a 300-run parameter sweep

22nd April 2026
Introduction
Speculative decoding is frequently cited as one of the more effective techniques for accelerating inference in large language models, with reported speedups typically falling in the 2x to 4x range over standard autoregressive decoding. The mechanism is straightforward: a smaller draft model proposes a short sequence of candidate tokens, and a larger target model verifies those proposals in a single parallel forward pass. Tokens that agree with the target are accepted in bulk; tokens that disagree trigger a fallback to standard decoding for the rejected portion. Verifying N candidate tokens in a single parallel pass reuses the same weight loads and takes roughly the same time as generating one token. When acceptance is high, the target model produces multiple tokens for the cost of one forward pass. When acceptance is low, the overhead of the draft model and verification is wasted, and throughput can fall below baseline.
This post documents a set of experiments evaluating the practical performance of speculative decoding on Apple Silicon, using MLX as the inference framework and DFlash as the speculative decoding implementation. The objective was twofold: to establish whether the commonly reported speedups hold on consumer-grade Apple hardware, and to identify which parameters materially affect the observed gains.
Experimental Setup
All experiments were run on a MacBook with the M5 Pro chip and 48 GB of unified memory. A reasonable heuristic for local inference is that roughly one gigabyte of memory is required per billion parameters, which places models in the 30 to 35 billion parameter range within reach of this configuration. Apple's unified memory architecture is useful in this context because the full memory pool is addressable by the GPU without explicit transfers.
The baseline inference loop used the mlx_lm package:
from mlx_lm import load, generate
from mlx_lm.models.cache import make_prompt_cache
MODEL = "mlx-community/Qwen3.5-35B-A3B-4bit"
model, tokenizer = load(MODEL)
cache = make_prompt_cache(model)
while True:
userinput = input("Enter prompt (or 'quit' to exit):")
if userinput.lower() == "quit":
print("Goodbye! 👋")
break
systemprompt = "You are a helpful assistant!"
messages = [{"role": "system", "content": systemprompt}, {"role": "user", "content": userinput}]
prompt = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
text = generate(model, tokenizer, prompt=prompt, prompt_cache=cache, max_tokens=10000, verbose=True)For the speculative decoding path, DFlash was installed from the official repository at https://github.com/z-lab/dflash. DFlash's moat here is that it replaces the autoregressive drafter with a block diffusion drafter that generates the entire draft block (16 tokens in the default config) in a single parallel forward pass, rather than one token at a time.
Initial Benchmark and Failure Mode
The first benchmark compared baseline decoding against DFlash using Qwen3.5-35B-A3B as the target and the corresponding DFlash draft model released by z-lab. The result was counter to expectations: DFlash produced throughput substantially lower than baseline in this configuration.
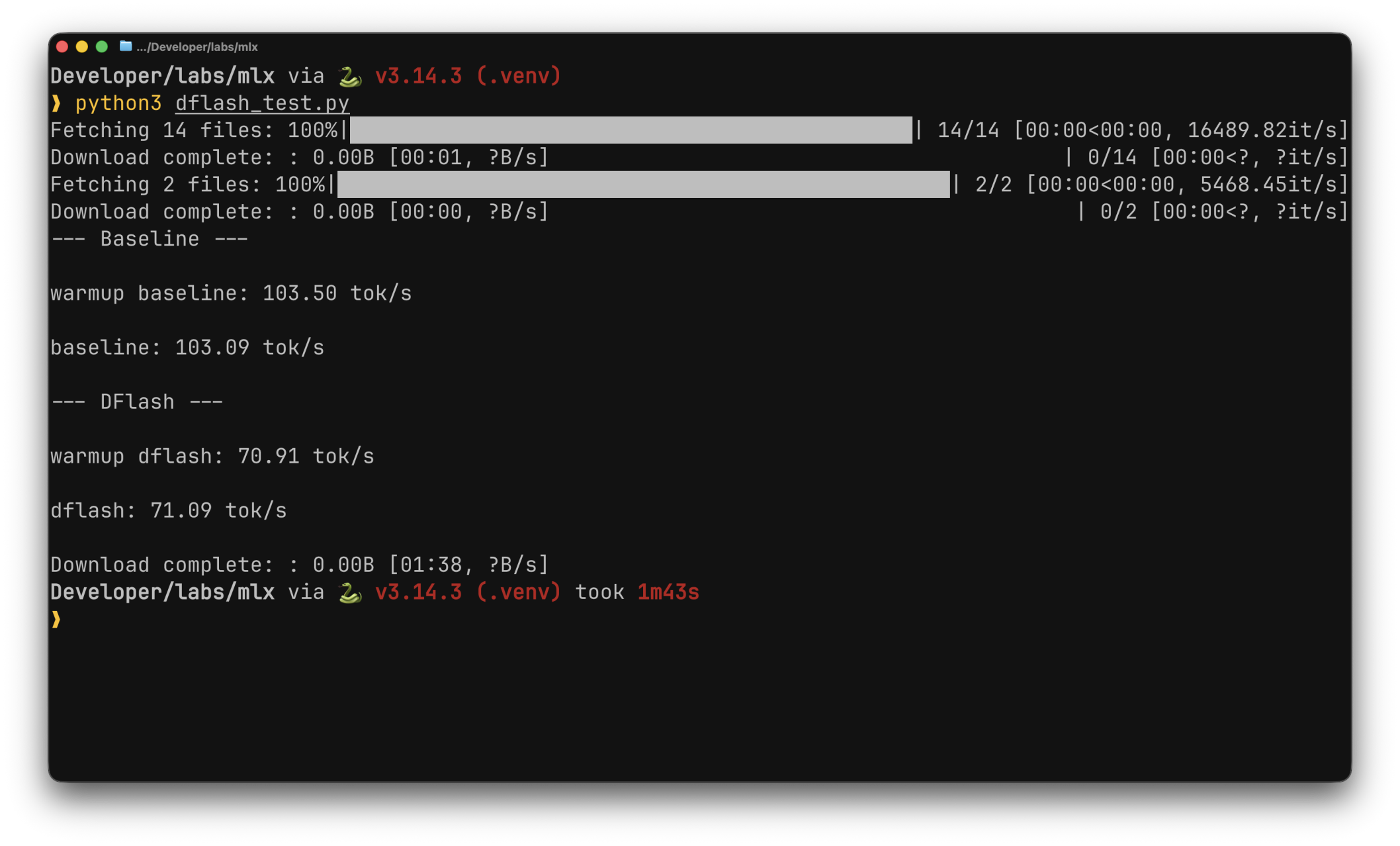
The cause was traced to a mismatch in model variants. The target model was a 4-bit quantized re-upload from the mlx-community organization, whereas the DFlash draft model had been trained against the unquantized original. Quantization alters the target's output distribution in ways that reduce draft-token acceptance, and once acceptance drops sufficiently, the overhead of running the draft model and verifying its outputs exceeds the savings from accepted tokens.
To remove quantization as a variable, the target and draft models were changed to the pair explicitly supported in the DFlash documentation:
- Target model:
Qwen/Qwen3.5-4B - Draft model:
z-lab/Qwen3.5-4B-DFlash
Under this configuration, DFlash delivered approximately 2x the throughput of baseline decoding, broadly consistent with reported performance on other platforms.
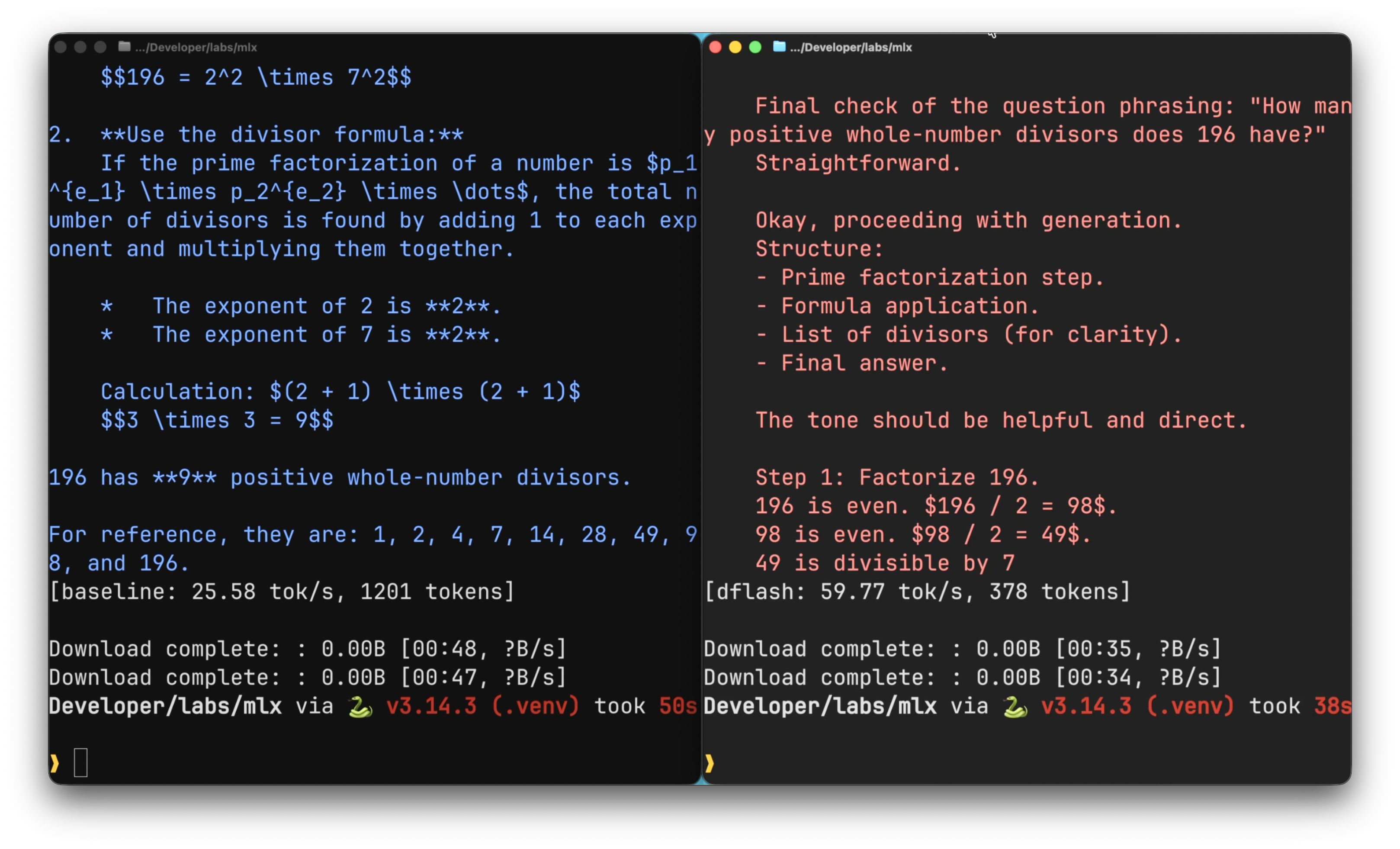
Parameter Sweep
With a working configuration established, the next step was to characterize how the observed speedup varied across the parameter space. Six variables were identified as candidates: prompt category, block size, sampling temperature, sliding window length, maximum token length, and thinking mode (enabled or disabled).
A sweep script was constructed to iterate through combinations of these variables, recording the speedup factor and draft-token acceptance rate for each run. This resulted in a total of 300 runs and all 300 configurations completed without failure.
Findings
Variables with Negligible Effect
Three of the six variables produced no measurable correlation with speedup: thinking mode, maximum token length, and sliding window length. For tuning purposes these can be treated as orthogonal to speculative decoding performance, which reduces the operational configuration space considerably.
Sampling Temperature
Temperature controls the stochasticity of the sampling distribution, with lower values producing more deterministic outputs. Acceptance rate peaked at approximately 0.3, with a clear downward trend above that point. This is consistent with the intuition that as the target distribution flattens, the probability of any single draft token matching the target's sampled token decreases. The peak at 0.3 rather than 0.0 is worth flagging, although the difference between the two was small; the degradation above 0.3 is the more robust signal in this data.
Block Size
Block size determines the number of tokens the draft model proposes per verification step. Smaller block sizes reduce wasted computation on rejected tokens but increase the frequency of verification; larger block sizes amortize verification cost but risk more wasted work when late tokens in the block are rejected.
Speedup increased from block size 4 through 8 to 16, with 16 as the peak. At block size 24 the speedup dropped sharply, and it remained roughly flat from 24 through 64. A configuration-specific optimum is expected from theory, since the marginal benefit of an additional token in the block is bounded by the probability that all preceding tokens are accepted. What this sweep contributes is a concrete data point for the Qwen3.5-4B target and draft pair on Apple Silicon, placing the optimum near 16.
Prompt Category
Prompts were grouped into seven categories: code, instruction, list, math, prose, question-answering, and random. The principal result was that more deterministic tasks produced higher speedups than open-ended ones. At the extreme, prompts in the random category occasionally produced speedup values below 1.0, meaning DFlash was slower than baseline on those inputs.
This result aligns with the mechanism of speculative decoding. The technique depends on the draft model producing token distributions that agree with those of the target. For constrained outputs such as code or structured lists, the distribution of plausible next tokens is narrow and the draft can match it reliably. For open-ended or explicitly random outputs, the distribution is broader, fewer draft tokens are accepted, and the overhead of running two models begins to dominate.
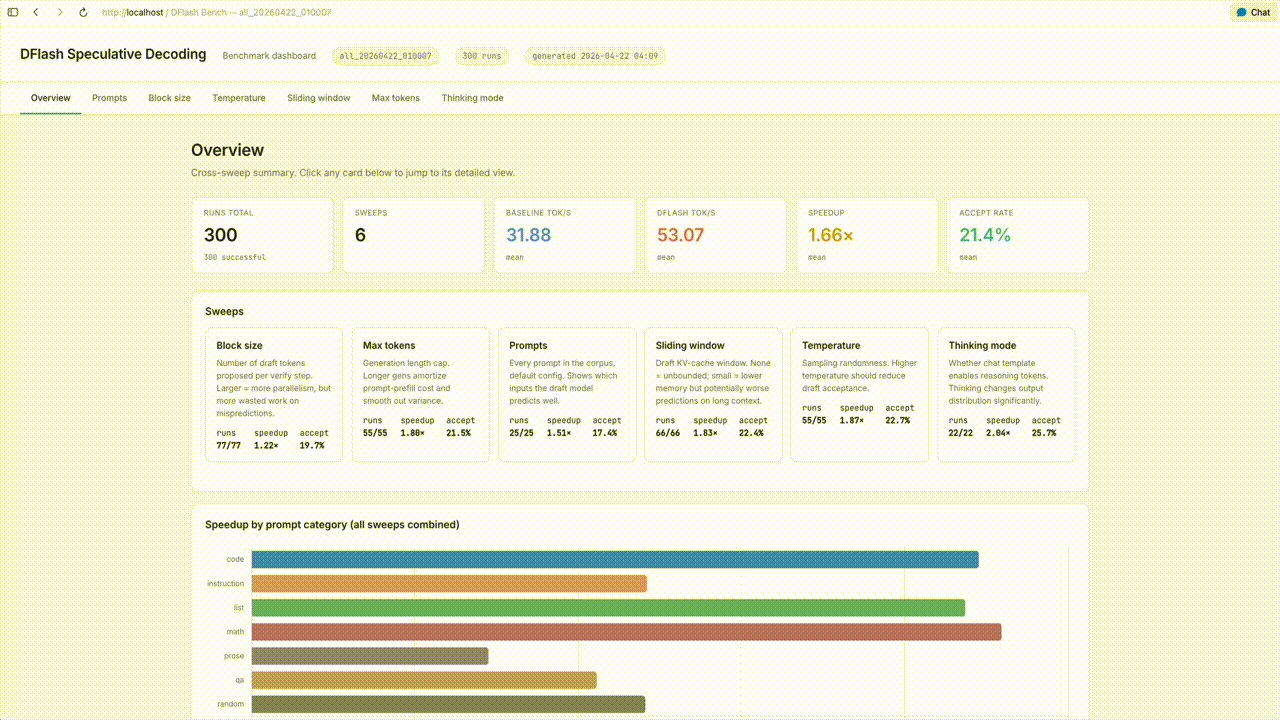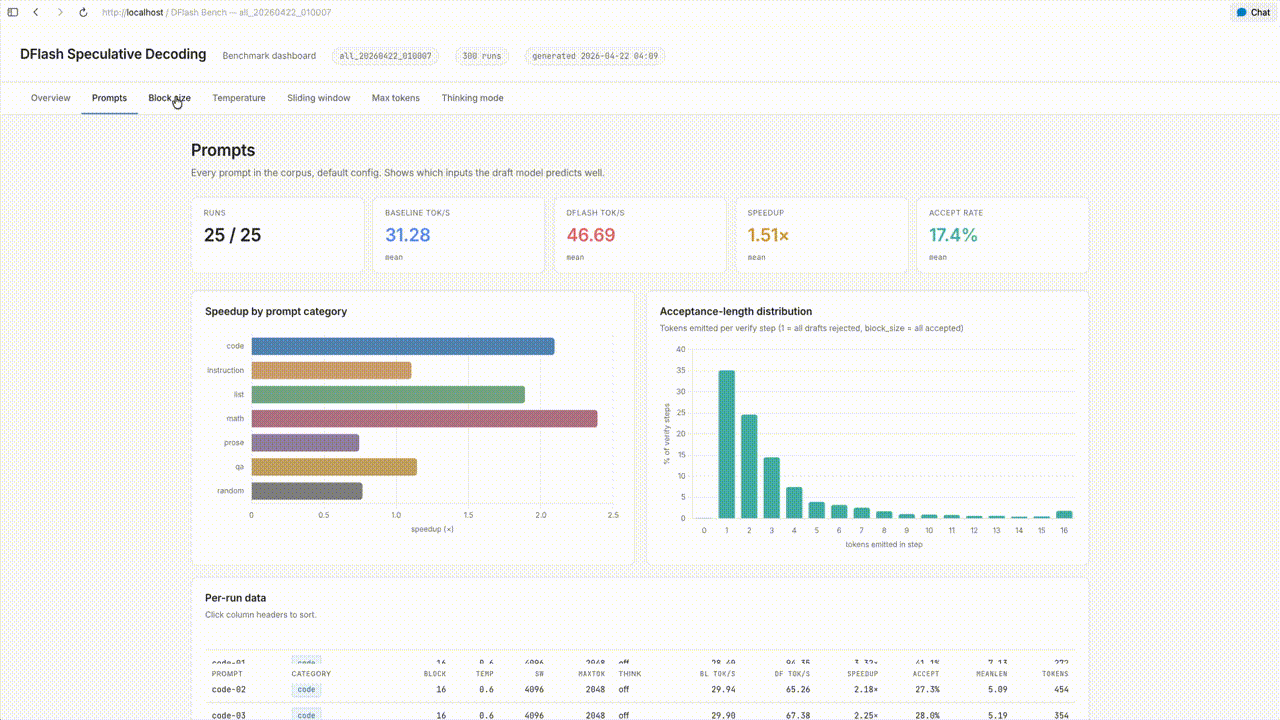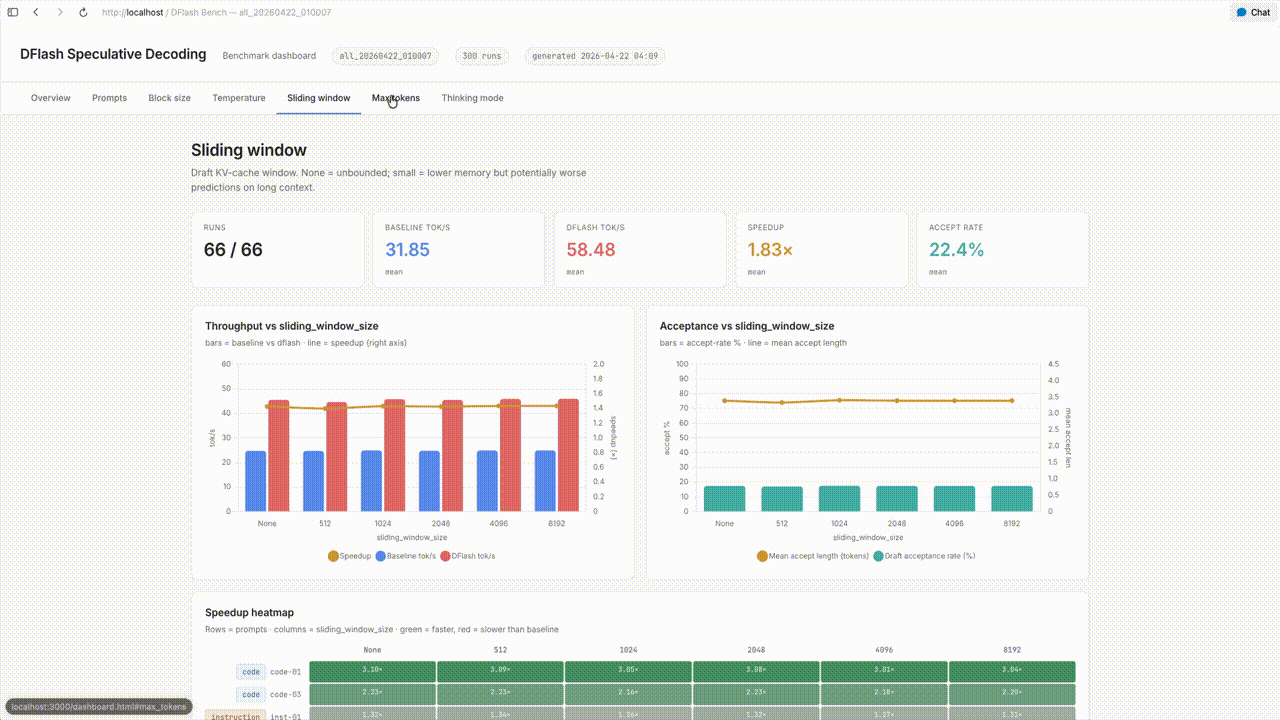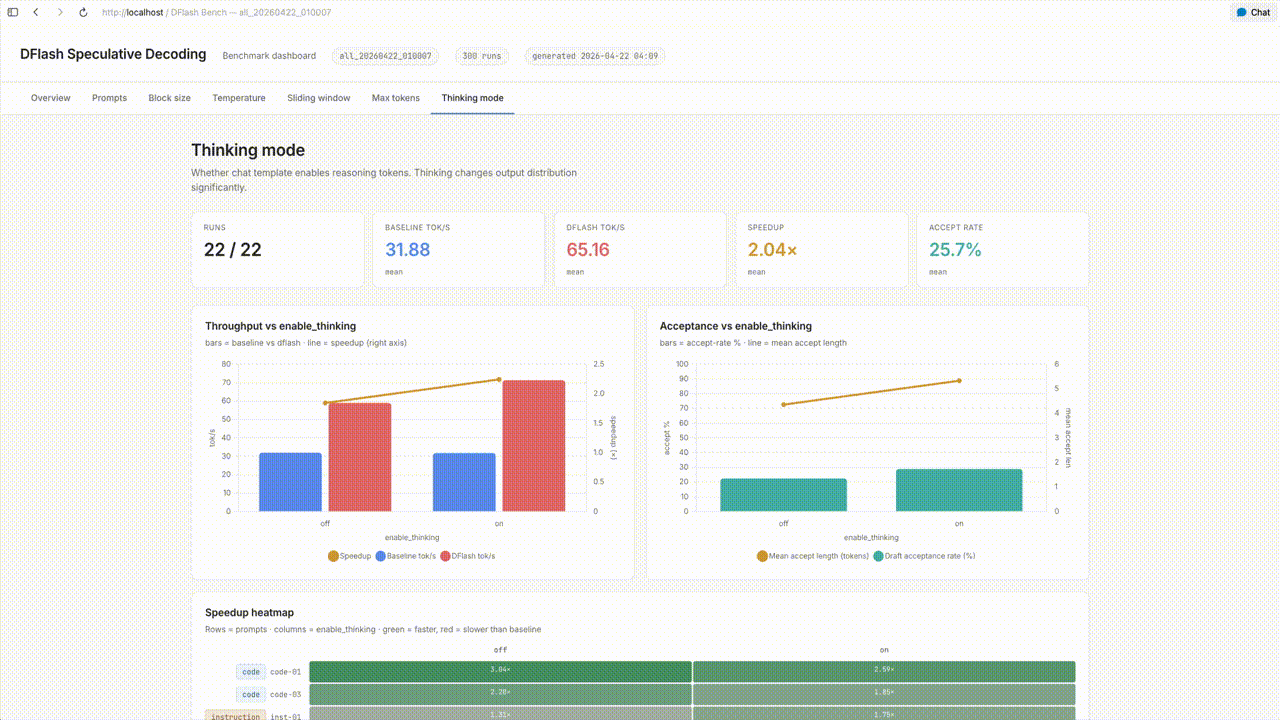
An interactive dashboard covering the full sweep is available here.
Conclusion
On Apple Silicon with MLX and DFlash, speculative decoding reproduces the approximately 2x speedup reported for other platforms, but only when the configuration respects the technique's assumptions. Three operational recommendations follow from the results.
First, draft and target models must match in their training variants. Introducing quantization on one side and not the other degrades acceptance rates to the point where speculative decoding is actively counterproductive.
Second, block size should be tuned per model pair. For the Qwen3.5-4B pair evaluated here, 16 tokens per block was optimal, and values above 24 offered no further benefit.
Third, speculative decoding should be gated by task type in production settings. Deterministic workloads such as code generation and structured output produce meaningful latency reductions; open-ended generation can show latency regressions and is a poor candidate for the technique.