Fine-tuning a model in MLX
Building a personal tweet-writing assistant on Apple Silicon

2nd June 2026

I kept staring at my own tweets wondering why some of them landed and some of them didn't. Same brain, same topics, wildly different engagement. After enough scrolling through my own analytics, a dumb question got stuck in my head: my high-engagement tweets clearly share something, some texture or rhythm I can't fully articulate - so could a model learn it for me? Could I hand it a rough thought and get back something shaped like the posts that actually worked?
The next question was how I'd train such a thing. And then it hit me that I was sitting in front of the answer the whole time. I have absurd compute on my desk. My MacBook can run real training loads locally. It's going to cost me zero dollars, and the everything happens completely local. Incredible.
I didn't want to fully fine-tune the model, though. Updating every weight of a base model is expensive, slow, and complete overkill for what I wanted, which was a style transfer - teach the thing my voice, not re-teach it the English language. That's exactly what LoRA is for.
What even is LoRA?
LoRA, or Low-Rank Adaptation, is one of the standard techniques for fine-tuning large language models without retraining the full parameter set. Instead of touching the base weights, it injects small trainable matrices into specific layers - typically the attention projections - and trains only those. The base model stays frozen. The trainable matrix count is tiny, often well under one percent of total parameters, which is exactly what makes it viable on consumer hardware where full fine-tuning isn't. On Apple Silicon, the mlx_lm package exposes LoRA training as a CLI command that reads a YAML config and writes adapter weights to disk. Perfect.
So the goal was concrete: train a LoRA adapter that turns a rough one-line note into a tweet styled after my own higher-engagement posts. Casual thought in, on-voice tweet out. The end product would ship as a personal adapter sitting on top of a Qwen3-4B base.
The path from "I scraped my tweets" to "I have a working adapter" was nowhere near as clean as I'd hoped. It took three full training runs and two distinct failure modes I had to diagnose: chat-template pollution that made the LoRA spit out reasoning-mode tokens on every single input, and plain undertraining because I didn't feed it enough examples. This is a rundown of all three runs - what broke, why, and what I'd tell myself to do differently.
Setting up
I picked mlx-community/Qwen3-4B-Instruct-2507-4bit as my base. The 2507 variant is the dedicated non-thinking instruct release of Qwen3-4B, distinct from the hybrid base model that supports both thinking and non-thinking modes. The 4-bit MLX quantization brings the on-disk size down to roughly 2.5 GB and keeps peak training memory under 4 GB - comfortably within reach on the laptop.
For data, I pulled 415 tweets from the past year, along with normalized engagement metrics: impressions, engagement rate, likes, retweets, replies, and bookmarks. Raw counts on their own are useless here - impression counts swing by an order of magnitude across posts thanks to algorithmic distribution and follower drift. So instead of absolute numbers I used a quality score normalized against impressions, and assigned tiers by percentile against my own distribution rather than some absolute threshold.
I built the data pipeline in three phases. In the first phase I enriched each tweet with computed fields: tier (top, mid, bottom) by quality-score percentile, engagement type (discussion, viral, saveable, validating, flop) via z-score across the normalized rates, and an inclusion flag that filtered out reposts, replies, very recent posts, and anything with too few impressions. In the second phase I generated prompt-pairs for each top and mid-tier tweet, using an external model to reverse-engineer the casual "thought" I might have jotted down before writing the tweet. My first iteration leaned on the Anthropic API for this; in the final pipeline I switched to running my own locally-quantized sabeshbesh/qwen3.6-27b-mlx-4bit model via mlx_lm. The third phase split everything into train, validation, and test sets.
After filtering, 125 tweets carried prompt pairs and made it into training. Validation held 18 examples, the test set held 12.
Run one
For the first run I went with the chat-message format - each training example a list of system, user, and assistant messages. I assumed mlx_lm.lora would tokenize these through the model's chat template and train accordingly. I configured 16 layers of LoRA adaptation at rank 8, applied to the four attention projection matrices. That came out to 2.6M trainable parameters, or 0.065 percent of the base model.
Training finished in 2m 35s, peak memory 3.2 GB. Validation loss bottomed at 1.59 at iteration 200, then climbed steadily to 2.18 by iteration 600 - the textbook overfit curve. I grabbed the iteration-200 checkpoint as best and ran inference.
This is what came out:
thought> modelhub is a cool app to manage local LLMs
→ <think>
</think>
you should try modelhub, it's an awesome app to help you manage your LLMs locally on your deviceA few things were obviously wrong. The model emitted <think></think> blocks before producing any tweet text. Some outputs leaked into Thai and Tamil character ranges. Others terminated with <tool_call> tokens. I tried throwing more LoRA layers at it and nudging the learning rate - none of it touched these artifacts.
Figuring out what went wrong
To see what the model had actually learned, I pushed the first training example back through the tokenizer and looked at the templated form:
<|im_start |>system
You are a tweet-writing assistant trained on the user's high-engagement posts...
<|im_end |>
<|im_start |>user
hackingwithswift is the best place to start learning SwiftUI <|im_end |>
<|im_start |>assistant
<think>
</think>
Try getting started with Swift/SwiftUI is very beginner friendly...
<|im_end |>There it was. The chat template for Qwen3-4B-Instruct-2507 inserts an empty <think></think> block at the start of every assistant message, even with thinking disabled. My LoRA had dutifully learned to emit that block before any content, because every single training example contained it. And once it had learned to reach for <think>, it got more and more likely to sample other special tokens that sit near <think> in the base model's training distribution - <tool_call>, the non-Latin tokens, all of it.
The fix was to throw out the chat-message format entirely and retrain on raw completions, where I just concatenate the prompt and the completion and teach the model to predict one from the other, with no chat scaffolding in sight.
Run two: completion format
I converted the training data to a flat {"prompt": "...", "completion": " ..."} structure - no system prompt, no chat tokens. While I was at it I bumped LoRA rank from 8 to 16, expanded the target keys to cover all attention and MLP projections, and dropped the learning rate from 1e-4 to 5e-5. Trainable parameters went up to 22M.
This retrain converged at iteration 125 with validation loss 2.62. On paper that's worse than v1's 1.59, but that comparison is a trap: v1's lower loss just reflected how easy it is to predict repeated <think></think> scaffolding, not anything about content quality. The v2 number actually measures content perplexity.
Then inference returned... empty strings. Great. After some digging I realized the problem: mlx_lm's generate function still expects the chat template applied to the input prompt at inference time, even though my training data never used it. Without the template wrapper, the model immediately sampled the end-of-sequence token and gave up. Wrapping the inference prompt in tok.apply_chat_template(...) fixed it.
This one's worth flagging loudly, because it bit me hard: training in completion format does not exempt you from chat-template processing at inference. The tokenizer wants its special boundary tokens regardless of how you structured the training data.
Output quality after the fix was a lot cleaner, but two problems stuck around. Hallucinated entities showed up constantly - invented products, papers, benchmarks. And whenever a prompt was short, the output went generic. Both pointed at the same root cause: 125 examples is simply below the threshold where a 22M-parameter LoRA can settle into stable, factual output.
Making more data
To break through that data ceiling, I generated synthetic prompt-pairs across seven topic clusters: iOS and Swift, Apple hardware, MLX, local LLMs, AI research, developer tools, and personal meta. This assortment of topics were chosen, because this is what I talk about - and are related to my life, so my tweets reflect them. I ran the generation through my locally-quantized 27B model, and for each call I included five randomly-sampled real prompt-pairs as few-shot examples. That anchoring mattered - it kept the synthetic data tied to my actual voice instead of letting the 27B base wander off into generic LLM-flavored phrasing.
The first pass was rough. The synthetic tweets over-indexed on hype phrases - "genuinely wild", "actually insane", "feels like cheating" - that never showed up in my real high-tier tweets. Emoji and hashtag rates were roughly three times my real distribution. And several outputs were just wrong, including one that confidently claimed Apple Silicon has VRAM rather than unified memory.
The second pass cleaned up most of that with three changes. I lowered sampling temperature from 0.85 to 0.65. I added explicit anti-pattern rules to the system prompt, listing the forbidden phrases and pushing for flat, dry phrasing. And I bolted on a post-filter that rejected any output containing a forbidden hype phrase or more than one emoji.
That left me with about 625 synthetic pairs. Combined with the 125 real pairs - oversampled twice to keep the real signal weighted - the training set landed at 875 examples.
Run three: the one that worked
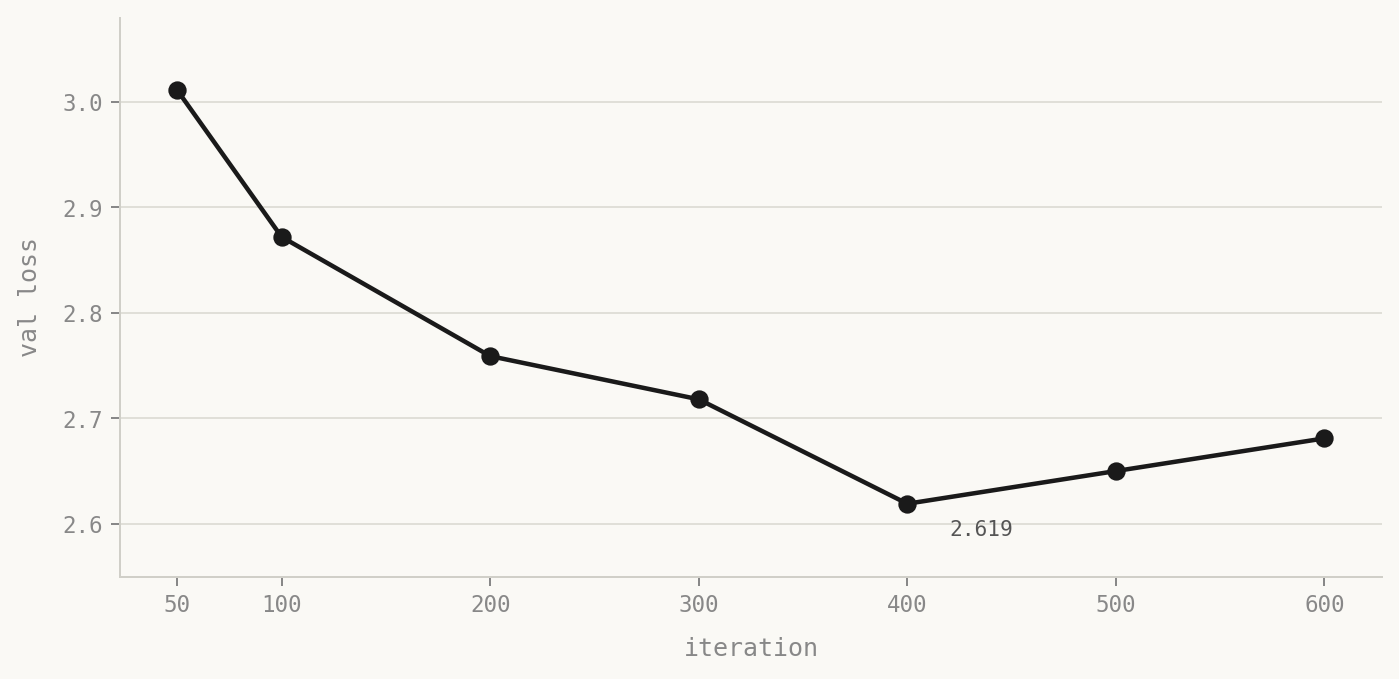
The third run used the augmented data with my v2 hyperparameters and a 600-iteration budget. Training took roughly eight minutes. Validation loss across the run:
| Iteration | Val Loss |
|---|---|
| 50 | 3.011 |
| 100 | 2.872 |
| 200 | 2.759 |
| 300 | 2.718 |
| 400 | 2.619 |
| 500 | 2.650 |
| 600 | 2.681 |
Best checkpoint at iteration 400. Train loss tracked val loss within about 0.9 the whole way, so no real overfit. The plateau between iteration 350 and 600 stayed inside a 0.07 band - which I read as the model having squeezed out everything this data has to give, not as overfitting creeping in.
Output quality was clearly better than v2. Voice consistency went up, hallucinations dropped, and the leftover <think> token emission became something I could just strip in post-processing without touching the actual tweet.
And finally - I was able to get a model, where I give it raw thoughts as input and it churns out text that resembles my twitter posting style - something I can use to maybe get viral soon!
Outcomes
Apart from the adapter (which I'm calling sabesh-tweeter), there were a few outcomes/learnings I took away from running these experiments.
On dataset size
A 22M-parameter LoRA on a 4B base needs more than 125 examples to converge to stable output. From this run, the threshold sits somewhere around 500 to 1000. Below 500, the model defaults to the average tweet shape and hallucinates entities to fill the gaps. Above 1000, returns drop off fast and synthetic-data dilution starts drowning out the real engagement signal. Around 750 examples worked well for me, with a 1:5 real-to-synthetic ratio and the real data oversampled twice.
1. Chat-template effects
Chat templates can inject special tokens into your training data that are invisible at the dataset level but produce very strong learned behavior in the resulting LoRA. For Qwen3-Instruct-2507, that's the <think></think> block. There are two ways to deal with it: train on completion format with no chat scaffolding, or use tokenizer flags like enable_thinking=False to suppress the offending blocks at template-application time. I went with the first. The second would honestly have been cleaner if I'd spotted it earlier.
2. Hyperparameters tweaking
For a style-transfer task on a 4B base, the settings that worked as a starting point were: rank 16 with alpha 32, 24 LoRA layers, all attention and all MLP projection keys, learning rate 5e-5, dropout 0.1, batch size 1, and an iteration budget roughly equal to the dataset size with eval and saves every 25 to 50 iterations. Lower ranks (8) and fewer layers (16) under-fit. Higher learning rates (1e-4) made validation loss unstable. Since the good config converges in a small fraction of the iteration budget, it's worth erring toward more frequent checkpoints. I also had to remove the MLP projection layers to get an optimized result (and just stick to the self attention keys).
3. Synthetic data quality
My locally-quantized 27B model produced synthetic tweets that were roughly 35 percent on-voice and 40 percent off-voice on the first pass, with the rest either factually wrong or structurally broken. Adding explicit anti-pattern guidance to the system prompt plus a regex post-filter pushed the on-voice fraction up to a usable level without needing a stronger generator. The lesson: synthetic data generation needs the same iteration discipline as any other data pipeline. A single-shot generation against a vague prompt gives you garbage.